I want to increase the speed of a some I/O I need to do which involves one pin pulsing like a square wave and another pin being either high or low at the transition to high of the square wave to transfer the data. This would not be a continuous square wave, just long enough to transmit 200 bits or so. I’m using a FEZ and am doing the toggling as follows.
for (int i = 0; i < localCopySize; i++)
{
byte a = localCopy[panel][i];
for (ushort bit = 0x80; bit != 0; bit >>= 1)
{
wrPin.Write(GpioPinValue.Low);
dataPin.Write(a & bit);
wrPin.Write(GpioPinValue.High);
}
}
I’m hoping to write this loop in native code, but don’t know how to do the writing to the pin. Could somebody please provide an example? My square period on the wrPin can be as fast as 1 us.
It’s an LED panel I’m driving. I have a memory area where I set the bits that represent which LEDs are on, then after I’ve done that I want to push that out to the LED driver chip (HT1632C). There are two or three panels, for each I set CS/ to low, then toggle the WR/ and while low set the Data/ and then raise WR/. I do that for each LED. The whole thing works, but I can see the sweeping across the 1500 LEDs as they get updated. Similar stuff on youtube with an Arduino seemed to go faster. I used the arduino code as my starting point.
Ok for driving right timing for LEDs, you have the option of using mosi pin on SPI and precalculate the bits. This is very accurate, if you can get the SPI clock to be dividable to what you need. Another option is to use signal generator feature.
Thanks Gus. I will see if I can figure out how to use the mosi pin. But to get back to my original question, how can I write to a digital pin from a native routine (which you’ve implied is possible). Is there a function I need to call or do I need to know the address of the register and do it via pointer?
This is not really supported and requires deep knowledge with processors/C++. Regardless, today we have blocked native code in TinyCLR for security reasons. We are still not sure if we are going to enable it back.
why not accumulate missing things ,and implementation of them on TINY CLR OS
instead of requesting RLP to return.
RLP such is will be very hard to do (because of file structure STM32H743xx) and no access on documentation since it not open like .NET Microframework to be able to debug …
so even such is (with a lot of space and speed) ,
most of things it can be done on the managed side
For us it’s a tricky situation as we need the speed of native computation rather than native access to the peripherals. Some of the computation we do is on large subsets of data (> 3MB) and requires complex calculation (think HMAC/SHA1 but custom)
Also. From time to time there is a need to process a large amount of data.
The current task is to create firmware of the signal spectrum by parameters. With different order and phase of its constituent harmonics. The number of harmonics is from 1 to 16 (for now).
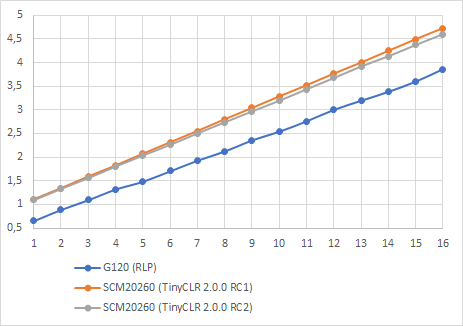
Comparison table for identical execution algorithms on RLP and TinyCLR2 for 16k flash points.